Flame Graph Reporter¶
The flame graph reporter generates an HTML file containing a flame graph representation of the allocations contributing to the tracked process’s peak memory usage.
Flame graphs are a way to visualize where your program is spending its memory. A few important things about flame graphs:
The flame graph displays the superposition of all stack traces that led to all memory allocations active at a given time (normally the time when the total amount of allocated memory was highest).
A stack trace is represented as a column of boxes, where each box represents one function call in that call stack.
The y-axis shows the stack depth. One special row represents the root, the next row represents the top level function calls that eventually led to memory being allocated, the next row represents things directly called by each of those top level calls, and so on. The furthest box from the root in any given vertical slice of the flame graph is the function that actually allocated the memory, and all of the boxes between it and the root tell you the full call stack that led to that allocation.
The x-axis does not show the passage of time, so the left-to-right ordering has no special meaning. Two functions called by the same caller will appear side by side in the flame graph, but can appear in either order.
The width of each box represents how much memory was allocated by that function call or its children. Wider boxes led to more memory being allocated than narrower ones, in proportion to their width.
A flame graph can’t tell you how many times a function was called, only how much memory that function allocated.
Flames versus Icicles¶
In what’s traditionally called a flame graph, each function in a call stack is shown directly above its caller, with the root at the bottom. This is called a “flame graph” because the wide base with narrowing columns above it looks sort of like a burning log with flames leaping into the air above it.
By default, Memray instead generates what’s sometimes called an “icicle graph”, which instead has the root at the top. In an icicle graph, each function is below its caller, and there is a wide ceiling that thinner columns descend from, like icicles hanging from a roof. We default to the icicle representation because it plays more nicely with the browser’s scroll bar: the most information-dense portion of an icicle graph is at the top of the screen, and the further down the page you scroll, the sparser the graphed data becomes, as shallower call stacks drop off.
You can switch between the flame graph orientation and the icicle graph orientation with this toggle button:
Whichever of these modes you choose, the data shown in the table is the same, just mirrored vertically.
Interpreting flame graphs¶
Memray’s default (icicle mode) flame graphs can be interpreted as follows:
The nodes at the bottom of the graph represent functions that allocated memory.
For quickly identifying the functions that allocated more memory directly, look for wide boxes along the bottom edge, as these show a single stack trace was responsible for a large chunk of the total memory of the snapshot that the graph represents.
Reading from the bottom up shows ancestry relationships. Every function was called by its parent, which is shown directly above it; the parent was called by its parent shown above it, and so on. A quick scan upward from a function identifies how it was called.
Reading from the top down shows code flow and the bigger picture. A function called every child function shown below it, which, in turn, called functions shown below them. Reading top down shows the big picture of code flow before various forks split execution into smaller shafts.
You can directly compare the width of function boxes: wider boxes mean more memory was allocated by the given node, so those are the most important to understand first.
Major forks in the graph (when a node splits into several nodes in the next level) can be useful to study: these nodes can indicate a logical grouping of code, where a function processes work in stages, each with its own function. It can also be caused by a conditional statement, which chooses which function to call.
If the application is multi-threaded, the stacks of all the threads that contribute to the memory peak will appear commingled in the graph by default.
And of course, if you switch from the “icicle” view to the “flame” view, the root drops to the bottom of the page, and call stacks grow upwards from it instead of downwards.
Simple example¶
def a(n):
return b(n)
def b(n):
return [c(n), d(n)]
def c(n):
return "a" * n
def d(n):
return "a" * n
a(100000)
This code allocates memory from the system allocator in just 2 places:
c(), and d(). This is how a flame graph (with the root at the
bottom) looks:

Here you can see that a() called b() and that b() called
c() and d(), which in turn did some allocations. As the boxes of
c() and d() are of the same width, you know that both allocated
the same amount of memory.
A more complete example¶
def a(n):
return [b(n), h(n)]
def b(n):
return c(n)
def c(n):
missing(n)
return d(n)
def missing(n):
return "a" * n
def d(n):
return [e(n), f(n), "a" * (n // 2)]
def e(n):
return "a" * n
def f(n):
return g(n)
def g(n):
return "a" * n * 2
def h(n):
return i(n)
def i(n):
return "a" * n
a(100000)
This code allocates memory from the system allocator in 5 places:
d(), e(), g(), i() and missing(). The associated
flame graph looks like this:

The top edge shows that function g() allocates the most memory,
d() is wider, but its exposed top edge is smaller, which means that
d() itself allocated less memory than the one allocated by the
functions called by it. Functions including b() and c() do
not allocate memory themselves directly; rather, the functions they
called did the allocating.
Functions beneath g() show its ancestry: g() was called by
f(), which was called by d(), and so on.
Visually comparing the widths of functions b() and h() shows
that the b() code path allocated about four times more than h().
The actual functions that did the allocations in each case were their
children.
A major fork in the code paths is visible where a() calls b()
and h(). Understanding why the code does this may be a major clue to
its logical organization. This may be the result of a conditional (if
conditional, call b(), else call h()) or a logical grouping of
stages (where a() is processed in two parts: b() and h()).
In our case we know it’s the second case, as a() is creating a list
with the result of b() and h().
If you look carefully you can notice that missing() allocates
memory, but it does not appear in the flame graph. This is because at
the time the largest memory peak was reached (when a() returned) the
memory allocated by missing() didn’t contribute at all to the total
amount of memory. This is because the memory allocated by missing()
is deallocated as soon as the call ends.
With this information, we know that if you need to choose a place to start
looking for optimizations, you should start looking at g(), then
e() and then i() (in that order) as these are the places that
allocated the most memory when the program reached its maximum. Of
course, the actual optimization may be done in the callers of these
functions, but you have a way to start understanding where to optimize.
Non-relevant frame hiding¶
The flame graph exposes a button to show or hide frames which might be distracting when interpreting the results, either because they were injected by Memray or because they are low-level implementation details of CPython. By default, frames tagged as irrelevant are hidden. You can reveal them by unchecking the Hide Irrelevant Frames checkbox:

Note that allocations in these frames will still be accounted for in parent frames, even if they’re hidden.
Memory Leaks View¶
When generating flame graphs, the --leaks option can be specified
to get information for memory that was leaked during the tracking
(i.e. allocated after tracking started and not deallocated by the time
tracking ended).
Important
The Python allocator doesn’t necessarily release memory to the system
when Python objects are deallocated and these can still appear as
“leaks”. When you use the --leaks option, you should usually
also run your application with the PYTHONMALLOC=malloc
environment variable set. See our documentation on python
allocators for details.
Split-Threads View¶
When generating flame graphs, the --split-threads option can be
specified to get thread-specific filtering on the flame graph.
If --split-threads is not specified, thread information is not
displayed on the flame graph. Instead, allocations occurring at the same
source location across different threads are grouped together. However,
if --split-threads is used, the allocation patterns of individual
threads can be analyzed.
When opening the report, the same merged thread view is presented, but a new “Filter Thread” dropdown will be shown. This can be used to select a specific thread to display a flame graph for that one thread:
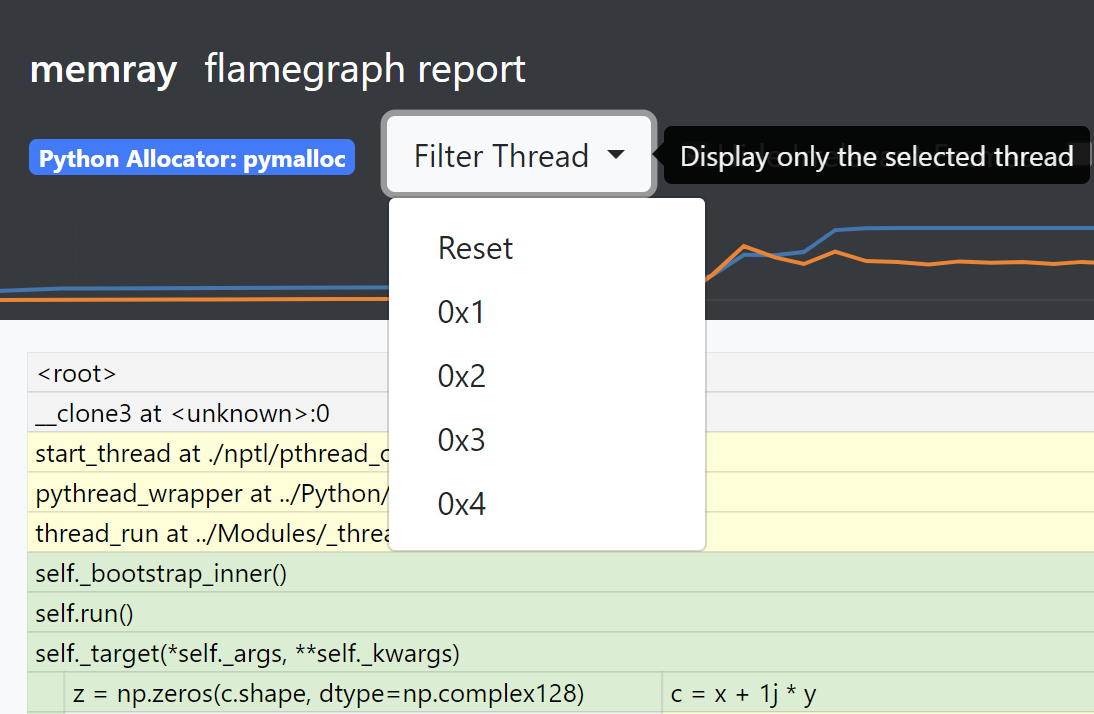
To go back to the merged view, the “Reset” entry can be used in the dropdown menu.
Note that the root node (displayed as <root>) is always present and is displayed as thread 0.
Inverted flame graphs¶
In a normal flame graph, the children of any given node are the functions called by that node, so the children of the root are thread entry points, and leaf nodes are functions that allocated memory but did not call any functions that allocated memory. This means that, if multiple distinct call stacks led to the same function allocating memory, there will be several leaf nodes for that same function (one per distinct call stack by which it was reached).
Memray also supports generating inverted flame graphs. In an inverted flame graph, the children of any given node are the functions that called that node, instead of the functions called by that node. This means that every function that allocated memory is a child of the root node, and the leaf nodes are thread entry points. If one thread entry point led to multiple distinct allocations, there will be several leaf nodes for that same entry point (one per distinct call stack by which an allocation was reached from it).
The inverted flame graph is very helpful in analyzing where memory is being spent in aggregate. If a function that allocates memory is called from multiple places, in the normal flame graph it will show up multiple times in the leaves, but in the inverted flame graph, all calls to one function will be aggregated and you’ll see the total amount allocated by it in one place.
You can supply the --inverted option when generating a flame graph to ask
Memray to produce an inverted flame graph.
Simple inverted flame graph example¶
def a():
return 1000000 * "a"
def a1():
return 1000000 * "a"
def b():
return a()
def c():
return b()
def d():
return b()
def f():
return g()
def e():
return g()
def g():
return c()
def main():
a = a1()
x = d()
y = e()
z = f()
return (x,y,z,a)
main()
This code allocates memory from the system allocator in just 2 places: a(),
and a1(). This is how the normal frame graph looks:
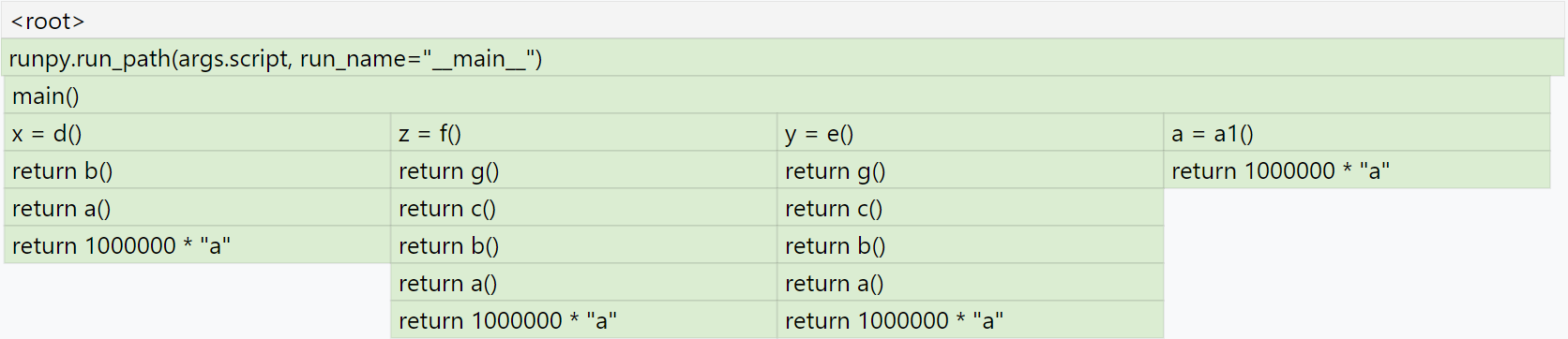
Here you can see that a() allocated memory three times when it was called
from b(), and a1() allocated memory when it was called from main().
If you generate the inverted flame graph with --inverted, you’ll instead
see something like:
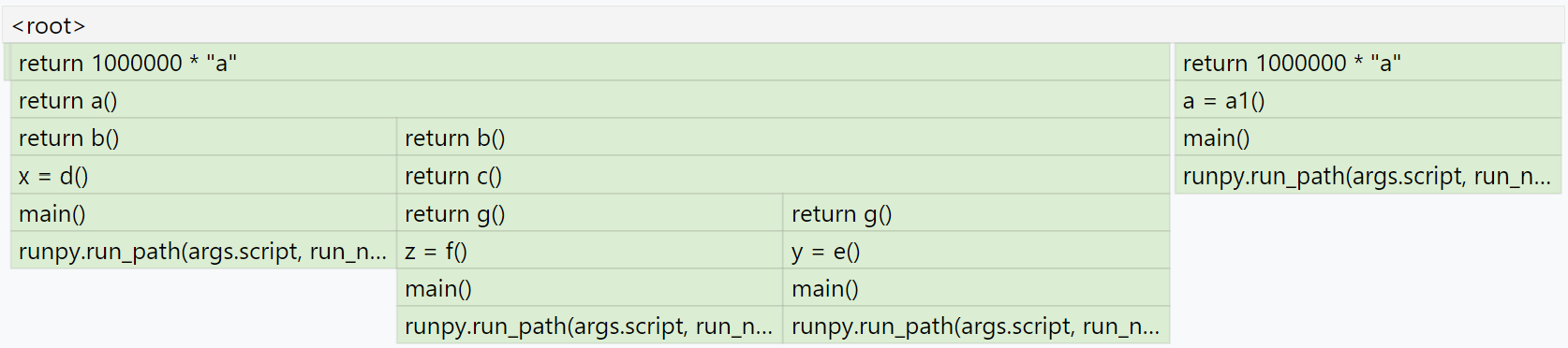
Here you can see that we have return 1000000 * "a" two times at the root.
The block for one of those calls is three times wider than the other because
a() was called three times from b(), while a1() was called only
once from main().
Temporal Flame Graphs¶
As noted above, the snapshots generated by memray flamegraph normally show
you only a single point in time. By default, that’s the point when the
process’s heap memory usage was highest. If you provide the --leaks option,
it instead shows the point when tracking ended, so that you can inspect what
was still allocated at that point.
If the --temporal option is provided, memray flamegraph will create
a unique type of flame graph that we call a “temporal flame graph”. In this
mode, the flame graph can show you not just one point in time, but instead the
usage over time (with approximately 10 millisecond granularity by default).
A temporal flame graph includes a chart of the process’s memory usage over time at the top of the page, and two sliders.
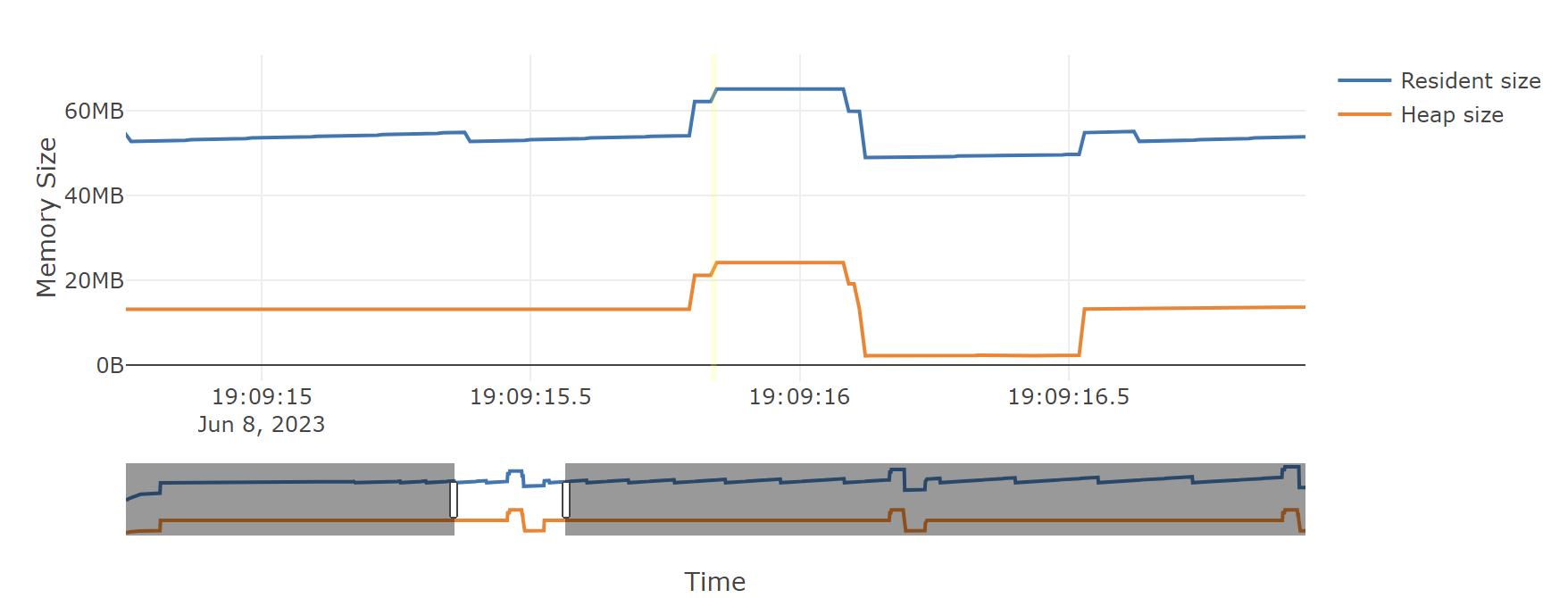
If you don’t use the --leaks option, the temporal flame graph will show you
data about the point in your chosen time range where heap memory usage was at
its highest. Because the sliders are initially on the two extreme ends, it
starts off showing you exactly what the non-temporal report would: the moment
during tracking when the highest amount of heap memory was used. Moving the
left slider lets you ignore any high water mark that happened before it, and
moving the right slider lets you ignore any high water mark that happened after
it. You can use these to focus in on what your process’s heap memory usage was
at any point during its run. The particular time slice within your chosen
window where Memray found the high water mark is highlighted, though you might
not be able to see it unless you zoom in enough that a 10 millisecond time
slice is wide enough.
If you use the --leaks option, the temporal flame graph will show you
allocations performed within the time window you select and not freed by the
end of it. Because the sliders are initially on the two extreme ends, it starts
off showing you exactly what the non-temporal leaks report would: allocations
performed at any point after tracking started and not freed before tracking
ended. Moving the left slider lets you ignore allocations made before the point
you select. Moving the right slider lets you look for allocations that hadn’t
been freed as of an arbitrary point in time, rather than only seeing ones that
weren’t freed before tracking stopped.
These temporal reports can be used to gain fine grained insight into how your process was using memory at any point during its run, which can be invaluable for understanding its memory usage patterns.
Note
Temporal flame graphs contain much more data than the default non-temporal flame graphs, so they’re slower to generate, and the generated HTML files are also larger. They can’t be generated from aggregated capture files, which don’t contain the necessary data about allocations over time. They also can’t be used for finding temporary allocations.
You can see an example of a temporal flame graph here.
Conclusion¶
Flame graphs are effective visualization tools for a memory snapshot of a program. They give an insightful visual map for the execution of Python code and allow navigating areas of interest, letting you identify where to start looking for improvements. Unlike other code-path visualizations such as acyclic graphs, flame graphs convey information intuitively using line lengths and can handle large-scale profiles, while usually remaining readable on one screen.
Basic Usage¶
The general form of the flamegraph subcommand is:
memray flamegraph [options] <results>
The only argument the flamegraph subcommand requires is the capture file
previously generated using the run subcommand.
The output file will be named memray-flamegraph-<input file name>.html
unless the -o argument was used to override the default name.
Reference¶
Generate an HTML flame graph for peak memory usage
usage: memray flamegraph [-h] [-o OUTPUT] [-f] [--temporal]
[--leaks | --temporary-allocation-threshold N | --temporary-allocations]
[--split-threads] [--inverted]
[--max-memory-records MAX_MEMORY_RECORDS]
results
Positional Arguments¶
- results
Results of the tracker run
Named Arguments¶
- -o, --output
Output file name
- -f, --force
If the output file already exists, overwrite it
Default:
False- --temporal
Generate a dynamic flame graph that can analyze allocations in a user-selected time range.
Default:
False- --leaks
Enables Memory Leaks View, where memory that was not deallocated is displayed, instead of peak memory usage.
- --temporary-allocation-threshold
Report temporary allocations, as opposed to leaked allocations or high watermark allocations. An allocation is considered temporary if at most N other allocations occur before it is deallocated. With N=0, an allocation is temporary only if it is immediately deallocated before any other allocation occurs.
Default:
-1- --temporary-allocations
Equivalent to --temporary-allocation-threshold=1
- --split-threads
Enables Split-Threads View, where each thread can be displayed separately. Allocations on the same source line across different threads are not merged, if this flag is passed.
- --inverted
Invert flame graph
Default:
False- --max-memory-records
Maximum number of memory records to display
Please submit feedback, ideas, and bug reports by filing a new issue at https://github.com/bloomberg/memray/issues