Exercise 2 - Clinging Onto Memory¶
Intro¶
Unlike some low level languages like C, Python will manage our memory for us and will free up memory that’s no longer needed. Python’s automatic memory management makes our lives easier, but sometimes, it may not work the way you would expect it to…
Working Through an Example¶
Let’s go through an example where memory management in Python doesn’t work how a person coming from other programming languages might expect.
Exercise¶
Take a look at the example in holding_onto_memory.py: how many MB of memory will it use at peak?
Take a guess, and then confirm by running memray and generating a flamegraph.
Expectations vs Reality¶
Let’s presume that we can’t mutate the original data, the best we can do is peak memory of 200MB:
for a brief moment in time both the original 100MB of data and the modified copy of the data will
need to be present. In practice, however, the actual peak usage will be 400MB as demonstrated by the
flamegraph:
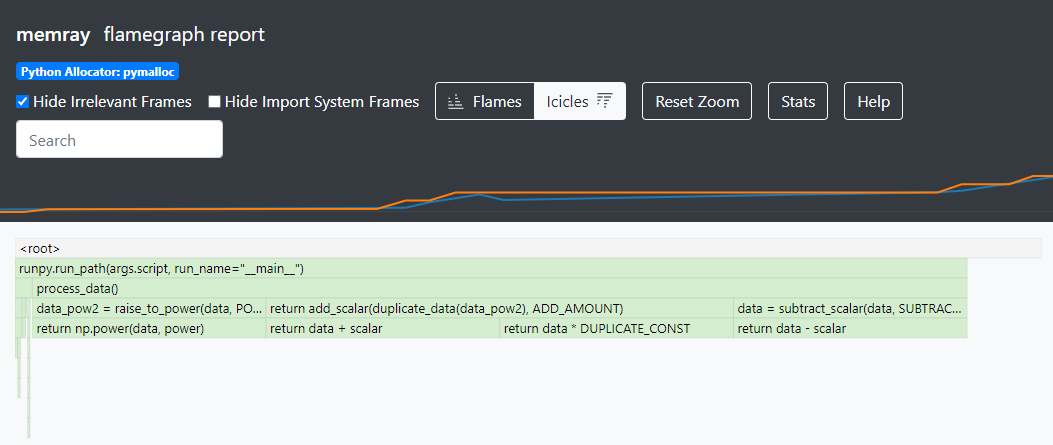
Examining our flame graph further, we can see that we peak at 400MB of allocated memory in
add_scalar due to four 100MB allocations that are all alive simultaneously:
The return value from
subtract_scalar, held by thedatavariable inprocess_dataThe return value from
raise_to_power, held by thedata_powvariable inprocess_dataThe return value from
duplicate_data, held by thedataargument inadd_scalarThe return value from
add_scalar, which is created and populated before the function returns and thedataargument goes out of scope
Challenge¶
Experiment with the code in holding_onto_memory.py and try to get the peak memory usage down to
200MB. Test your solutions by running the unit test in tests/test_exercise_2.py and examine them
with the help of memray reports.
Solutions¶
Toggle to see the sample solutions
After examining the flame graph, we can see that the problem is caused by local variables which are
no longer needed, but continue to use memory until process_data() has finished running.
Therefore, we need to refactor the method in a way that does not use unnecessary variables to store
data that will not be read afterwards. There are two main approaches we can use to solve our issue
here:
Avoiding local variables in
process_data()all together and instead returning the result of nested function calls:def process_data(): # no extra reference to the original array return add_scalar( duplicate_data( raise_to_power( subtract_scalar( load_xMb_of_data(SIZE_OF_DATA_IN_MB), SUBTRACT_AMOUNT ), POWER_AMOUNT ) ), ADD_AMOUNT )
Reassigning one variable: we can create a single variable, and re-use it multiple times to store the new value of the manipulated array. This way, we will only hold one array in memory at a time, instead of holding on to older versions of the mutated array unnecessarily:
def process_data(): # reusing the local variable instead of allocating more space # this approach is called 'hidden mutability' data = load_xMb_of_data(SIZE_OF_DATA_IN_MB) data = subtract_scalar(data, SUBTRACT_AMOUNT) data = raise_to_power(data, POWER_AMOUNT) data = duplicate_data(data) data = add_scalar(data, ADD_AMOUNT) return data
Full code solution here.
Conclusion¶
Typically, holding onto data in memory a little longer than needed is not a big issue. However, when we are working with large objects, we should be particularly careful. Over-allocating unnecessary memory can lead to running out of memory on the machine (especially for Linux VMs which are typically smaller than physical machines).
Memray can be a helpful tool when trying to debug where we are over-allocating memory unnecessarily.
More resources:
A more detailed walkthrough with a similar example
Another related article about unnecessary memory allocation
A great article on mutability and immutability in Python